
基础数据结构及其对应的C++ STL容器的使用
特别感谢:
- Hello 算法:https://www.hello-algo.com/
- OI Wiki: https://oi-wiki.org/
- labuladong的算法小抄 ISBN 978-7-121-39933-6
什么是数据结构?
数据结构的定义:
在 Wikipedia 中,数据结构(Data structure)通常被定义为:
Data structure is a specialized format for organizing, processing, retrieving, and storing data. It defines the relationship between the data and the operations that can be performed on it. Data structures are used in many applications and are fundamental to the design and implementation of algorithms.
简译为:
数据结构是用于组织、处理、检索和存储数据的专门格式。它定义了数据之间的关系以及可以对其执行的操作。数据结构在许多应用中都有使用,是算法设计和实现的基础。
数据结构的分类:
常见的数据结构包括数组、链表、栈、队列、哈希表、树、堆、图,它们可以从“逻辑结构”和“物理结构”两个维度进行分类。
由于篇幅和演讲时间限制,我们只选讲逻辑结构部分,如需要了解物理结构,请查阅: 数据结构分类 - Hello 算法。
如图 1-1 所示,逻辑结构可分为“线性”和“非线性”两大类。线性结构比较直观,指数据在逻辑关系上呈线性排列;非线性结构则相反,呈非线性排列。
- 线性数据结构:数组、链表、栈、队列、哈希表,元素之间是一对一的顺序关系。
- 非线性数据结构:树、堆、图、哈希表。
非线性数据结构可以进一步划分为树形结构和网状结构。
- 树形结构:树、堆、哈希表,元素之间是一对多的关系。
- 网状结构:图,元素之间是多对多的关系。
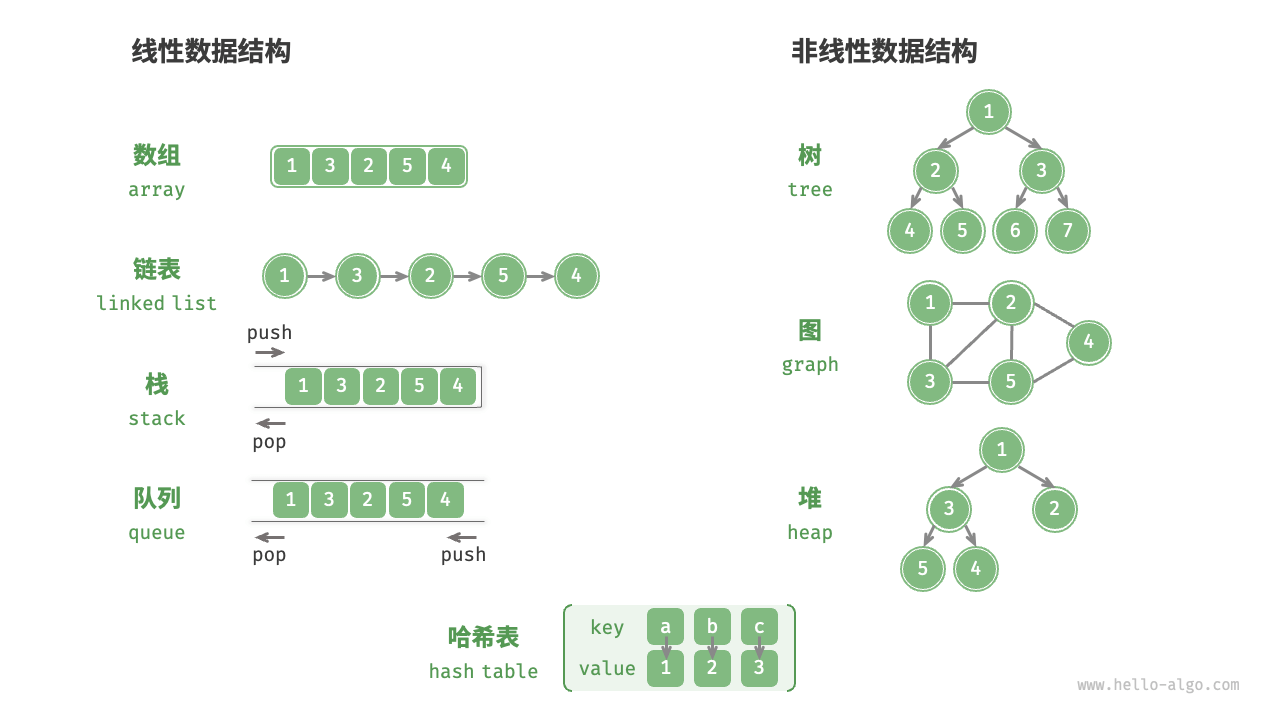
本篇将会提到的数据结构如下表:
| 数据结构 | 对应C++ STL容器(适配器) | 例题 |
|---|---|---|
| 数组 | Array 或 原生数组 | |
| 链表 | list(双向链表) 或 forward_list(单向链表) | LC21 |
| 列表(动态数组) | vector | LC26 |
| 字符串 | string | LC14 |
| 队列 | queue(单端队列) 或 deque(双端队列) | LC2073 |
| 栈 | stack | LC20 |
| 优先队列(堆) | priority_queue | LC1046 |
| 平衡二叉搜索树 | set 或 map | LC1, LC217 |
| 哈希表 | unordered_set 和 unordered_map | LC1, LC217 |
数组与链表
数组
数组(array)是一种线性数据结构,其将相同类型的元素存储在连续的内存空间中。我们将元素在数组中的位置称为该元素的索引(index)。图 2-1 展示了数组的主要概念和存储方式。
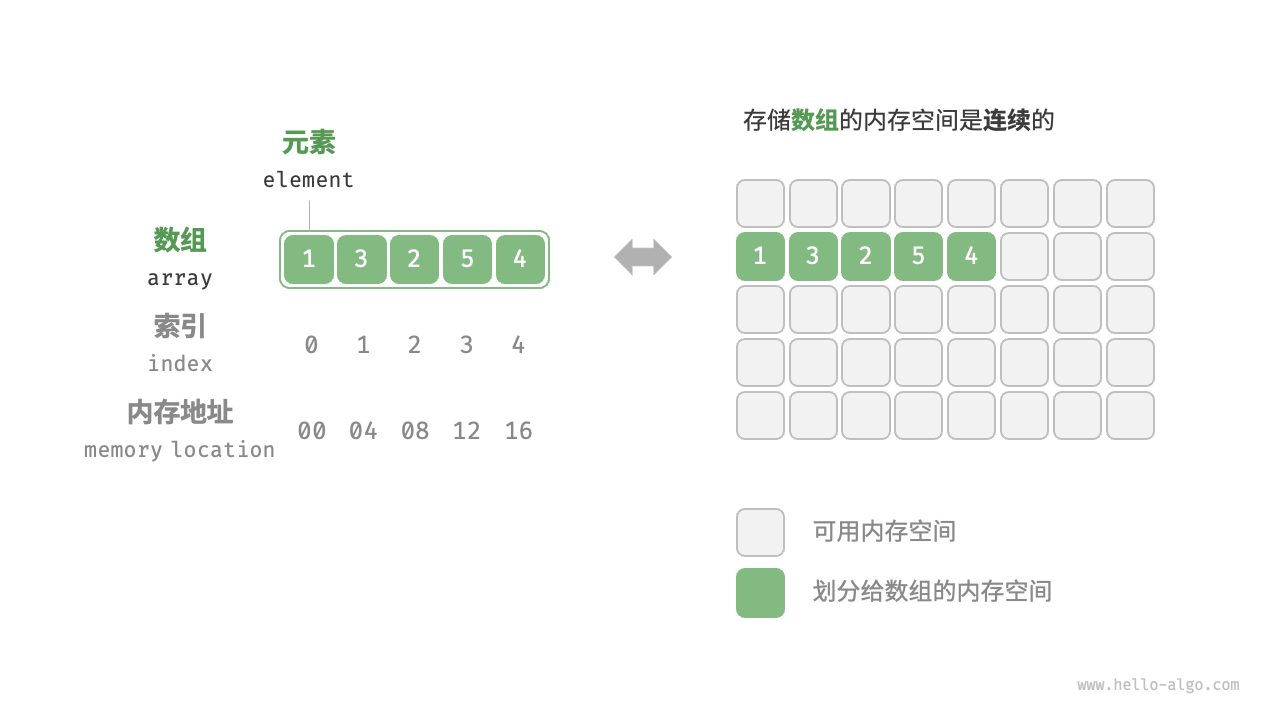
数组常用操作
1. 初始化数组
/* 初始化数组 */
// 存储在栈上
int arr[5];
int nums[5] = { 1, 3, 2, 5, 4 };
// 存储在堆上(需要手动释放空间)
int* arr1 = new int[5];
int* nums1 = new int[5] { 1, 3, 2, 5, 4 };2. 访问元素
数组元素被存储在连续的内存空间中,这意味着计算数组元素的内存地址非常容易。给定数组内存地址(首元素内存地址)和某个元素的索引,我们可以计算得到该元素的内存地址,从而直接访问该元素。
在数组中访问元素非常高效,我们可以在 时间内随机访问数组中的任意一个元素。
/* 随机访问元素 */
int randomAccess(int *nums, int size) {
// 在区间 [0, size) 中随机抽取一个数字
int randomIndex = rand() % size;
// 获取并返回随机元素
int randomNum = nums[randomIndex];
return randomNum;
}3. 插入元素
数组元素在内存中是“紧挨着的”,它们之间没有空间再存放任何数据。如图 2-2 所示,如果想在数组中间插入一个元素,则需要将该元素之后的所有元素都向后移动一位,之后再把元素赋值给该索引。
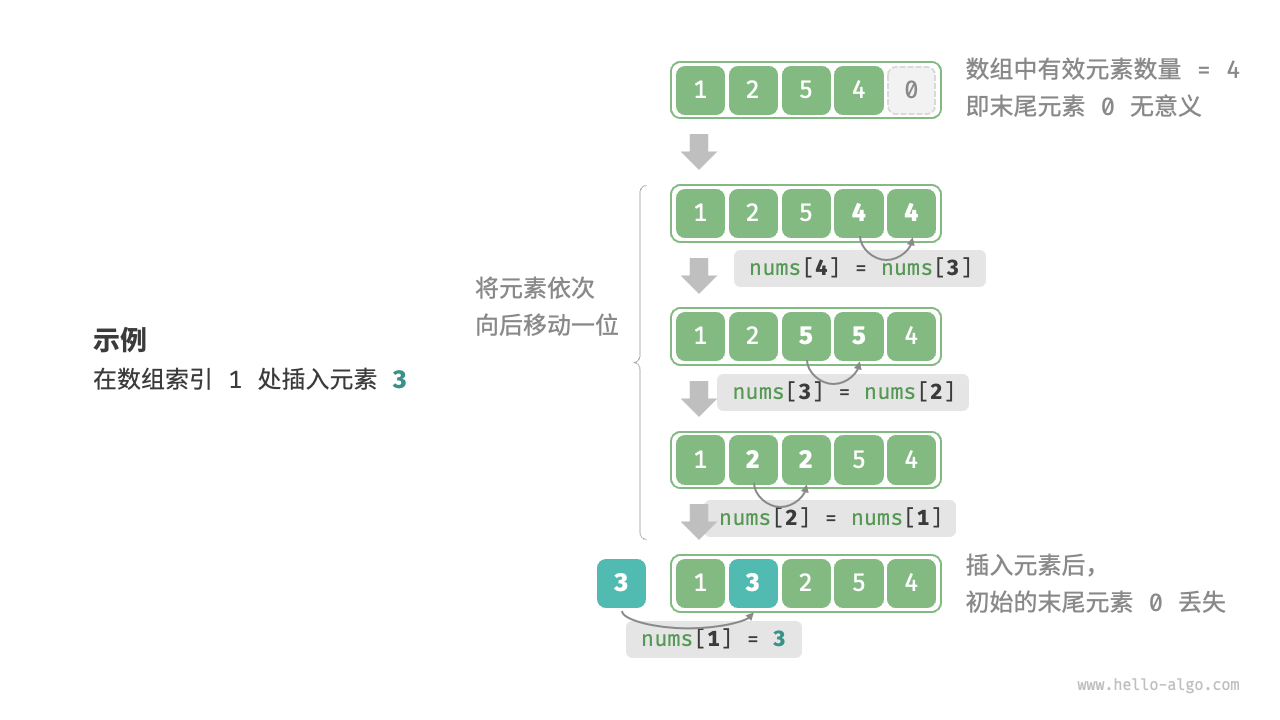
值得注意的是,由于数组的长度是固定的,因此插入一个元素必定会导致数组尾部元素“丢失”。我们将这个问题的解决方案留在“列表”章节中讨论。
/* 在数组的索引 index 处插入元素 num */
void insert(int *nums, int size, int num, int index) {
// 把索引 index 以及之后的所有元素向后移动一位
for (int i = size - 1; i > index; i--) {
nums[i] = nums[i - 1];
}
// 将 num 赋给 index 处的元素
nums[index] = num;
}4. 删除元素
同理,如图 2-3 所示,若想删除索引 i 处的元素,则需要把索引 i 之后的元素都向前移动一位。
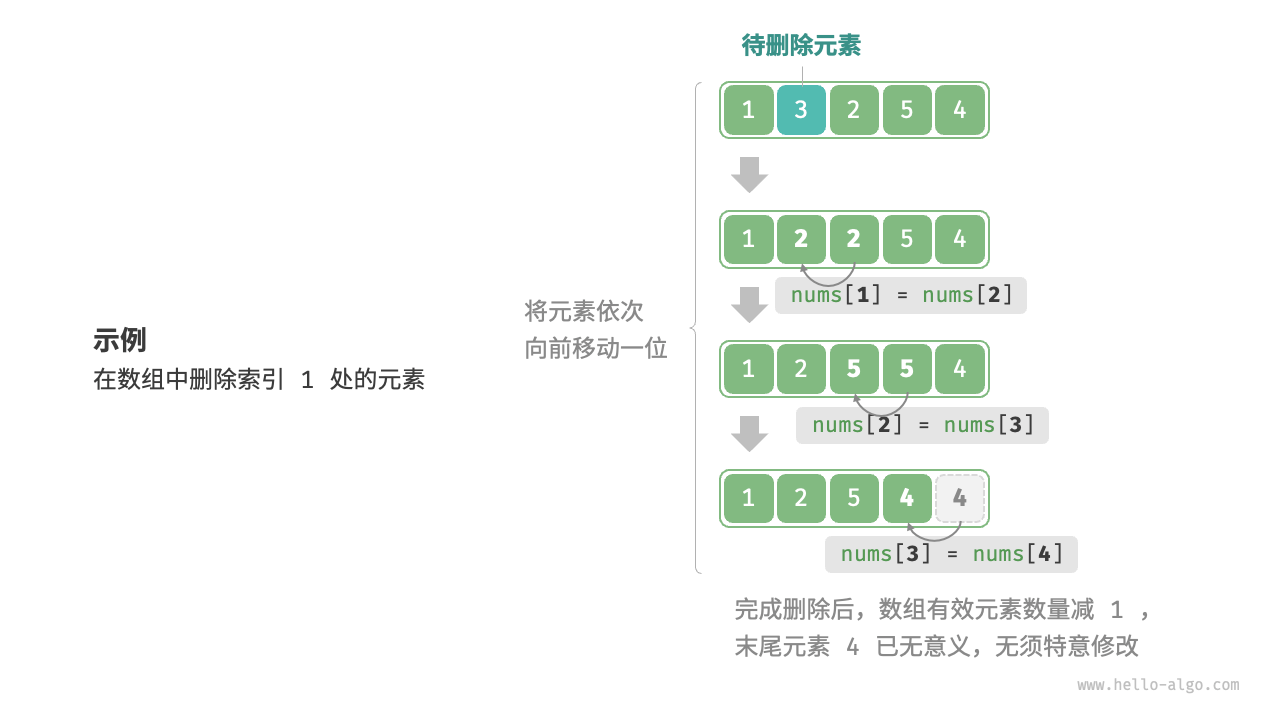
请注意,删除元素完成后,原先末尾的元素变得“无意义”了,所以我们无须特意去修改它。
/* 删除索引 index 处的元素 */
void remove(int *nums, int size, int index) {
// 把索引 index 之后的所有元素向前移动一位
for (int i = index; i < size - 1; i++) {
nums[i] = nums[i + 1];
}
}总的来看,数组的插入与删除操作有以下缺点。
- 时间复杂度高:数组的插入和删除的平均时间复杂度均为 ,其中 为数组长度。
- 丢失元素:由于数组的长度不可变,因此在插入元素后,超出数组长度范围的元素会丢失。
- 内存浪费:我们可以初始化一个比较长的数组,只用前面一部分,这样在插入数据时,丢失的末尾元素都是“无意义”的,但这样做会造成部分内存空间浪费。
5. 遍历数组
/* 遍历数组 */
void traverse(int *nums, int size) {
int count = 0;
// 通过索引遍历数组
for (int i = 0; i < size; i++) {
count += nums[i];
}
}6. 查找元素
在数组中查找指定元素需要遍历数组,每轮判断元素值是否匹配,若匹配则输出对应索引。
因为数组是线性数据结构,所以上述查找操作被称为“线性查找”。
/* 在数组中查找指定元素 */
int find(int *nums, int size, int target) {
for (int i = 0; i < size; i++) {
if (nums[i] == target)
return i;
}
return -1;
}7. 扩容数组
在复杂的系统环境中,程序难以保证数组之后的内存空间是可用的,从而无法安全地扩展数组容量。因此在大多数编程语言中,数组的长度是不可变的。
如果我们希望扩容数组,则需重新建立一个更大的数组,然后把原数组元素依次复制到新数组。这是一个 的操作,在数组很大的情况下非常耗时。代码如下所示:
/* 扩展数组长度 */
int *extend(int *nums, int size, int enlarge) {
// 初始化一个扩展长度后的数组
int *res = new int[size + enlarge];
// 将原数组中的所有元素复制到新数组
for (int i = 0; i < size; i++) {
res[i] = nums[i];
}
// 释放内存
delete[] nums;
// 返回扩展后的新数组
return res;
}数组的优点与局限性
数组存储在连续的内存空间内,且元素类型相同。这种做法包含丰富的先验信息,系统可以利用这些信息来优化数据结构的操作效率。
- 空间效率高:数组为数据分配了连续的内存块,无须额外的结构开销。
- 支持随机访问:数组允许在 O(1) 时间内访问任何元素。
- 缓存局部性:当访问数组元素时,计算机不仅会加载它,还会缓存其周围的其他数据,从而借助高速缓存来提升后续操作的执行速度。
连续空间存储是一把双刃剑,其存在以下局限性。
- 插入与删除效率低:当数组中元素较多时,插入与删除操作需要移动大量的元素。
- 长度不可变:数组在初始化后长度就固定了,扩容数组需要将所有数据复制到新数组,开销很大。
- 空间浪费:如果数组分配的大小超过实际所需,那么多余的空间就被浪费了。
链表
内存空间是所有程序的公共资源,在一个复杂的系统运行环境下,空闲的内存空间可能散落在内存各处。我们知道,存储数组的内存空间必须是连续的,而当数组非常大时,内存可能无法提供如此大的连续空间。此时链表的灵活性优势就体现出来了。
链表(linked list)是一种线性数据结构,其中的每个元素都是一个节点对象,各个节点通过“引用”相连接。引用记录了下一个节点的内存地址,通过它可以从当前节点访问到下一个节点。
链表的设计使得各个节点可以分散存储在内存各处,它们的内存地址无须连续。
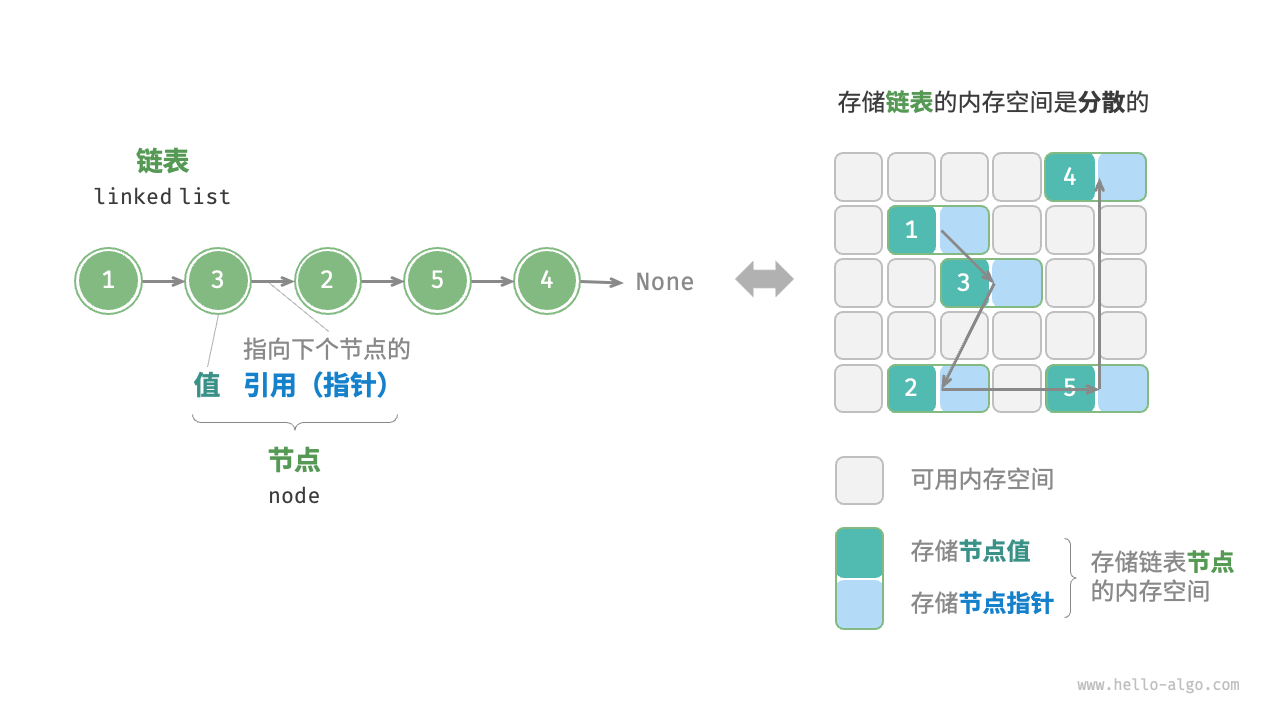
观察图 2-4 ,链表的组成单位是节点(node)对象。每个节点都包含两项数据:节点的“值”和指向下一节点的“引用”。
- 链表的首个节点被称为“头节点”,最后一个节点被称为“尾节点”。
- 尾节点指向的是“空”,它在 Java、C++ 和 Python 中分别被记为
null、nullptr和None。 - 在 C、C++、Go 和 Rust 等支持指针的语言中,上述“引用”应被替换为“指针”。
如以下代码所示,链表节点 ListNode 除了包含值,还需额外保存一个引用(指针)。因此在相同数据量下,链表比数组占用更多的内存空间。
/* 链表节点结构体 */
struct ListNode {
int val; // 节点值
ListNode *next; // 指向下一节点的指针
ListNode(int x) : val(x), next(nullptr) {} // 构造函数
};链表常用操作
1. 初始化链表
/* 初始化链表 1 -> 3 -> 2 -> 5 -> 4 */
// 初始化各个节点
ListNode* n0 = new ListNode(1);
ListNode* n1 = new ListNode(3);
ListNode* n2 = new ListNode(2);
ListNode* n3 = new ListNode(5);
ListNode* n4 = new ListNode(4);
// 构建节点之间的引用
n0->next = n1;
n1->next = n2;
n2->next = n3;
n3->next = n4;数组整体是一个变量,比如数组 nums 包含元素 nums[0] 和 nums[1] 等,而链表是由多个独立的节点对象组成的。我们通常将头节点当作链表的代称,比如以上代码中的链表可记作链表 n0 。
2. 插入节点
在链表中插入节点非常容易。如图 2-5 所示,假设我们想在相邻的两个节点 n0 和 n1 之间插入一个新节点 P ,则只需改变两个节点引用(指针)即可,时间复杂度为 。
相比之下,在数组中插入元素的时间复杂度为 ,在大数据量下的效率较低。
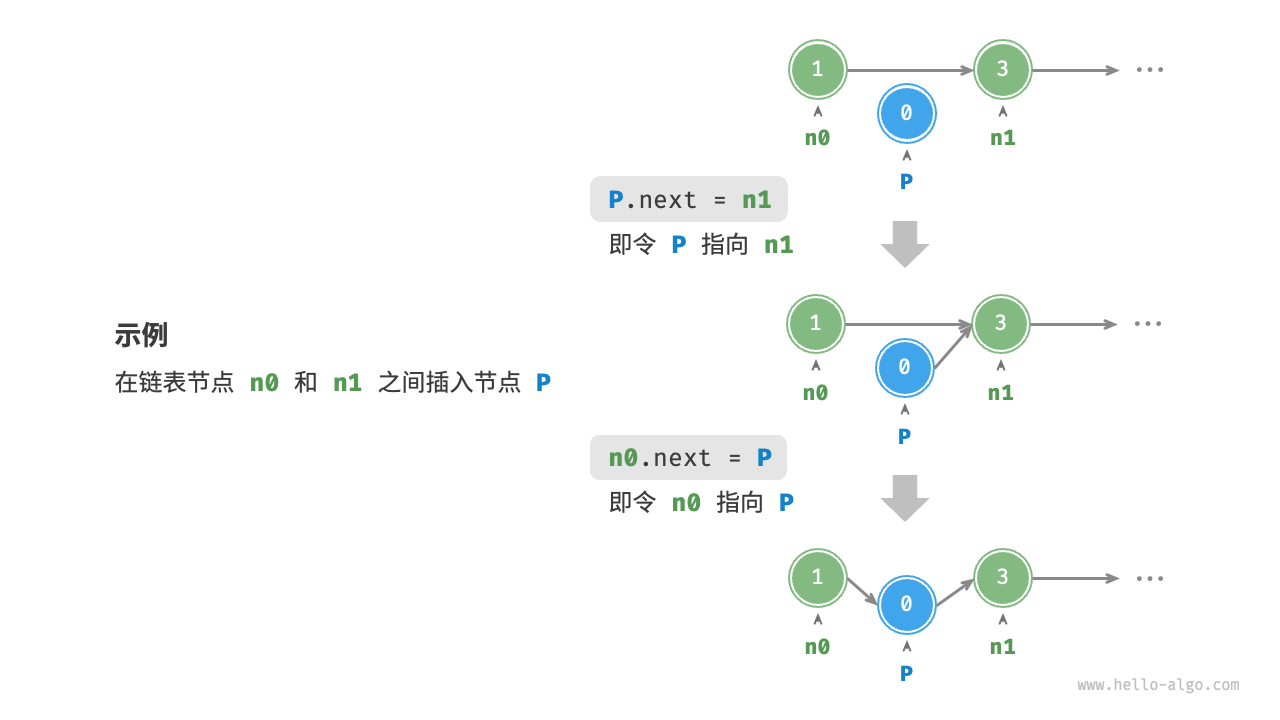
/* 在链表的节点 n0 之后插入节点 P */
void insert(ListNode *n0, ListNode *P) {
ListNode *n1 = n0->next;
P->next = n1;
n0->next = P;
}3. 删除节点
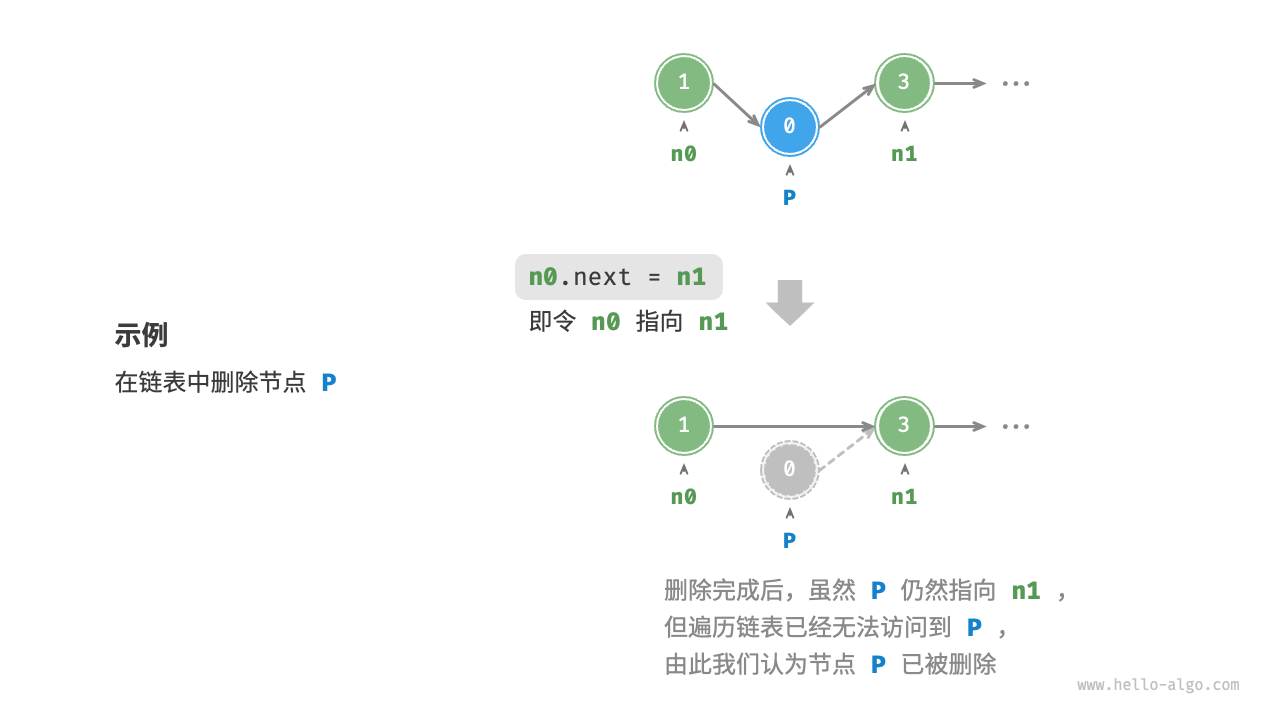
如图 2-6 所示,在链表中删除节点也非常方便,只需改变一个节点的引用(指针)即可。
请注意,尽管在删除操作完成后节点 P 仍然指向 n1 ,但实际上遍历此链表已经无法访问到 P ,这意味着 P 已经不再属于该链表了。
/* 删除链表的节点 n0 之后的首个节点 */
void remove(ListNode *n0) {
if (n0->next == nullptr)
return;
// n0 -> P -> n1
ListNode *P = n0->next;
ListNode *n1 = P->next;
n0->next = n1;
// 释放内存
delete P;
}4. 访问节点
在链表中访问节点的效率较低。如上一节所述,我们可以在 时间下访问数组中的任意元素。链表则不然,程序需要从头节点出发,逐个向后遍历,直至找到目标节点。也就是说,访问链表的第 个节点需要循环 轮,时间复杂度为 。
/* 访问链表中索引为 index 的节点 */
ListNode *access(ListNode *head, int index) {
for (int i = 0; i < index; i++) {
if (head == nullptr)
return nullptr;
head = head->next;
}
return head;
}5. 查找节点
遍历链表,查找其中值为 target 的节点,输出该节点在链表中的索引。此过程也属于线性查找。代码如下所示:
/* 在链表中查找值为 target 的首个节点 */
int find(ListNode *head, int target) {
int index = 0;
while (head != nullptr) {
if (head->val == target)
return index;
head = head->next;
index++;
}
return -1;
}数组 vs. 链表
表 2-1 总结了数组和链表的各项特点并对比了操作效率。由于它们采用两种相反的存储策略,因此各种性质和操作效率也呈现对立的特点。
| 数组 | 链表 | |
|---|---|---|
| 存储方式 | 连续内存空间 | 分散内存空间 |
| 容量扩展 | 长度不可变 | 可灵活扩展 |
| 内存效率 | 素占用内存少、但可能浪费空间 | 元素占用内存多 |
| 访问元素 | ||
| 添加元素 | ||
| 删除元素 |
常见链表类型
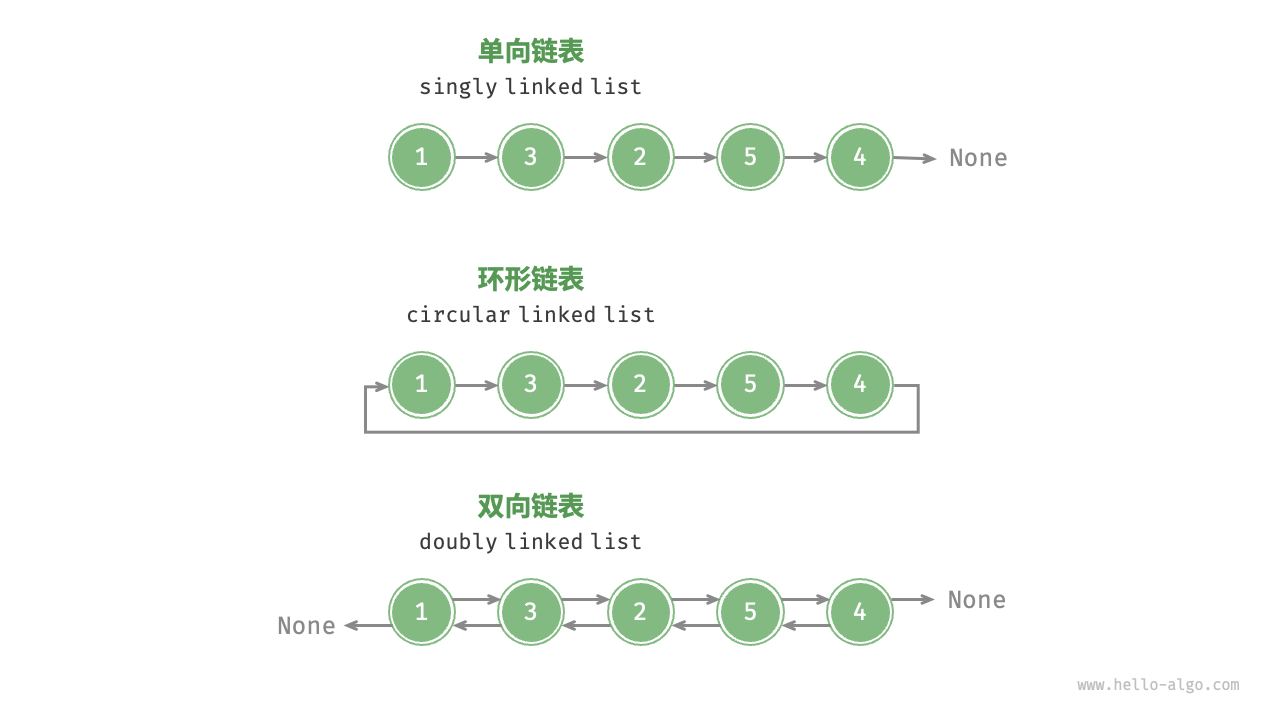
如图 2-7 所示,常见的链表类型包括三种。
- 单向链表:即前面介绍的普通链表。单向链表的节点包含值和指向下一节点的引用两项数据。我们将首个节点称为头节点,将最后一个节点称为尾节点,尾节点指向空
None。 - 环形链表:如果我们令单向链表的尾节点指向头节点(首尾相接),则得到一个环形链表。在环形链表中,任意节点都可以视作头节点。
- 双向链表:与单向链表相比,双向链表记录了两个方向的引用。双向链表的节点定义同时包含指向后继节点(下一个节点)和前驱节点(上一个节点)的引用(指针)。相较于单向链表,双向链表更具灵活性,可以朝两个方向遍历链表,但相应地也需要占用更多的内存空间。
列表(动态数组)
列表(list)是一个抽象的数据结构概念,它表示元素的有序集合,支持元素访问、修改、添加、删除和遍历等操作,无须使用者考虑容量限制的问题。列表可以基于链表或数组实现。
- 链表天然可以看作一个列表,其支持元素增删查改操作,并且可以灵活动态扩容。
- 数组也支持元素增删查改,但由于其长度不可变,因此只能看作一个具有长度限制的列表。
当使用数组实现列表时,长度不可变的性质会导致列表的实用性降低。这是因为我们通常无法事先确定需要存储多少数据,从而难以选择合适的列表长度。若长度过小,则很可能无法满足使用需求;若长度过大,则会造成内存空间浪费。
为解决此问题,我们可以使用动态数组(dynamic array)来实现列表。它继承了数组的各项优点,并且可以在程序运行过程中进行动态扩容。
实际上,许多编程语言中的标准库提供的列表是基于动态数组实现的,例如 Python 中的 list 、Java 中的 ArrayList 、C++ 中的 vector 和 C# 中的 List 等。在接下来的讨论中,我们将把“列表”和“动态数组”视为等同的概念。
列表常用操作
1. 初始化列表
/* 初始化列表 */
// 需注意,C++ 中 vector 即是本文描述的 nums
int n = 7, m = 8;
// 初始化一个int类型的空数组
vector<int> nums1;
// 初始化一个大小为 n 的数组nums,数组中的默认值都是 0
vector<int> nums(n);
// 初始化一个元素为 1, 3, 2, 5, 4 的数组 nums
vector<int> nums = { 1, 3, 2, 5, 4 };
// 初始化一个大小为 n 的数组nums,数组中的值都是 2
vector<int> nums(n, 2);
// 初始化一个二维 int 数组 dp
vector<vector<int>> dp;
// 初始化一个大小为 m * n 的布尔数组 dp,其中的值都为 true
vector<vector<bool>> dp(m, vector<bool>(n, true));2. 访问元素
/* 访问元素 */
int num = nums[1]; // 访问索引 1 处的元素
/* 更新元素 */
nums[1] = 0; // 将索引 1 处的元素更新为 0
/* 得到最后一个元素的引用 */
nums.back();
int a = nums.back(); // 将数组最有一个元素的值赋值给变量 a
nums.back() = 1; // 修改数组最后一个元素的值为 13. 插入与删除元素
相较于数组,列表可以自由地添加与删除元素。在列表尾部添加元素的时间复杂度为 ,但插入和删除元素的效率仍与数组相同,时间复杂度为 。
/* 清空列表 */
nums.clear();
/* 在尾部添加元素 */
nums.push_back(1);
nums.push_back(3);
nums.push_back(2);
nums.push_back(5);
nums.push_back(4);
/* 在中间插入元素 */
nums.insert(nums.begin() + 3, 6); // 在索引 3 处插入数字 6
/* 删除元素 */
nums.erase(nums.begin() + 3); // 删除索引 3 处的元素
/* 删除数组最后一个元素 */
nums.pop_back();4. 遍历列表
/* 通过索引遍历列表 */
int count = 0;
// nums.size() 返回数组长度
for (int i = 0; i < nums.size(); i++) {
count += nums[i];
}
/* 直接遍历列表元素 */
count = 0;
for (int num : nums) {
count += num;
}5. 拼接列表
/* 拼接两个列表 */
vector<int> nums1 = { 6, 8, 7, 10, 9 };
// 将列表 nums1 拼接到 nums 之后
nums.insert(nums.end(), nums1.begin(), nums1.end());6. 排序列表
/* 排序列表 */
sort(nums.begin(), nums.end()); // 排序后,列表元素从小到大排列7. 判断数组是否为空数组
nums.empty(); // 返回 true 或 false 代表数组是否为空8. 交换数组元素的值
swap(nums[0], nums[1]); // 交换 nums 数组中索引为 0 和 索引为 1 处的值列表例题 LC26 - 删除有序数组中的重复项
给你一个 非严格递增排列 的数组 nums ,请你 原地 删除重复出现的元素,使每个元素 只出现一次 ,返回删除后数组的新长度。元素的 相对顺序 应该保持 一致 。然后返回 nums 中唯一元素的个数。
考虑 nums 的唯一元素的数量为 k ,你需要做以下事情确保你的题解可以被通过:
- 更改数组
nums,使nums的前k个元素包含唯一元素,并按照它们最初在nums中出现的顺序排列。nums的其余元素与nums的大小不重要。 - 返回
k。
示例 1:
输入:nums = [1,1,2]
输出:2, nums = [1,2,_]
解释:函数应该返回新的长度 2 ,并且原数组 nums 的前两个元素被修改为 1, 2 。不需要考虑数组中超出新长度后面的元素。
示例 2:
输入:nums = [0,0,1,1,1,2,2,3,3,4]
输出:5, nums = [0,1,2,3,4]
解释:函数应该返回新的长度 5 , 并且原数组 nums 的前五个元素被修改为 0, 1, 2, 3, 4 。不需要考虑数组中超出新长度后面的元素。
思路
我们可以利用双指针的技巧来解决这个问题。由于输入数组已经是排序好的,只需要一次遍历即可找出所有的唯一元素。双指针的思想如下:
- 初始化指针:使用两个指针,
i和j,其中:i用来遍历数组,指向当前正在检查的元素。j用来标记我们数组中唯一元素的末尾位置。
- 遍历数组:
- 对于每个
i,如果nums[i]与nums[i-1]不同,那么我们就认为nums[i]是一个新的唯一元素,将它移到位置j。 - 每次发现一个新的唯一元素,
j递增,表示当前唯一元素的数量。
- 对于每个
- 返回结果:
- 最终,
j会存储数组中唯一元素的个数,即新的长度。
- 最终,
- 注意事项:
- 如果数组长度只有一个元素,直接返回长度 1。
- 由于题目要求原地修改数组,我们只需要返回
j,并且不需要关注数组中j之后的元素。
#include <bits/stdc++.h>
using namespace std;
using int64 = int64_t;
class Solution {
public:
int removeDuplicates(vector<int>& nums) {
// 如果数组长度为1,直接返回1
if (nums.size() == 1) return 1;
// 初始化双指针,i 用于遍历数组,j 用于标记唯一元素的末尾位置
int i = 0, j = 0;
// 遍历整个数组,i 从0到nums.size() - 1
for (; i < nums.size() - 1; ++i) {
// 如果当前元素不等于下一个元素,则更新唯一元素的末尾
if (nums[i] != nums[i + 1]) {
nums[j++] = nums[i]; // 将当前元素移到位置 j
}
}
// 处理数组的最后一个元素
if (j - 1 >= 0 && nums[i] != nums[j - 1]) {
nums[j] = nums[i]; // 将最后一个元素移到位置 j
}
// 返回唯一元素的个数,即数组的新长度
return j + 1;
}
};字符串
字符串,就是由字符连接而成的序列。
字符串常用操作
1. 初始化
// s 是一个空字符串 ""
string s;
// s 是字符串 "abc"
string s = "abc";2. 常用成员函数(方法)
// 返回字符串的长度
size_t size();
// 判断字符串是否为空
bool empty();
// 在字符串尾部插入一个字符 c
void push_back(char c);
// 删除字符串尾部的那个字符
void pop_back();
// 返回从索引 pos 开始,长度为 len 的子字符串
string substr(size_t pos, size_t len);下面是具体使用例:
// 声明并初始化空字符串 s
string s;
// 给 s 赋值为 "abcd"
s = "abcd";
// 输出 'c'
cout << s[2];
// 在 s 尾部插入字符 'e'
s.push_back('e');
// 输出 "abcde"
cout << s;
// 输出 "dce"
cout << s.substr(2, 3);
// 在 s 尾部拼接字符串 "xyz"
s += "xyz";
// 输出 "abcdexyz"
cout << s;字符串 std::string 的很多操作和动态数组 std::vector 比较相似。此外,在 C++ 中两个字符串内容的相等性可以直接用双等号运算符判断 if (s1 == s2)。
字符串例题 LC14 - 最长公共前缀
编写一个函数来查找字符串数组中的最长公共前缀。
如果不存在公共前缀,返回空字符串 ""。
示例 1:
输入:strs = [“flower”,“flow”,“flight”]
输出:“fl”
示例 2:
输入:strs = [“dog”,“racecar”,“car”]
输出:""
解释:输入不存在公共前缀。
思路
我们可以通过逐一比较字符串的字符来找出它们的公共前缀。具体的实现步骤如下:
- 初始化前缀:首先,我们可以将第一个字符串作为初始的公共前缀。
- 逐一与后续字符串比较:接着,我们通过逐个字符串与当前公共前缀进行比较。如果发现某个字符串与公共前缀不匹配,我们就把公共前缀截断到匹配的部分。
- 处理特殊情况:如果某个字符串完全没有公共前缀,直接返回空字符串
""。
解法
以下是实现的详细步骤:
- 选择第一个字符串作为前缀:我们假设第一个字符串就是公共前缀。
- 与其他字符串逐一比较:从第二个字符串开始,逐个和前缀比较。每次比较时,如果某个字符不相同,就更新公共前缀,直到找到最长公共前缀。
- 更新前缀:每次比较后,如果找到了公共部分,更新前缀为当前公共部分。
- 终止条件:如果在某次比较中,公共前缀变成了空字符串,说明没有公共前缀,直接返回空字符串。
#include <bits/stdc++.h>
using namespace std;
using int64 = int64_t;
class Solution {
public:
// 这是查找最长公共前缀的函数
string longestCommonPrefix(vector<string>& strs) {
// 将第一个字符串作为初始前缀
string prefix = strs[0];
// 遍历数组中的其他字符串
for (int strIndex = 1; strIndex < strs.size(); ++strIndex) {
// 如果当前前缀为空,直接返回空字符串
if (prefix.empty()) return prefix;
// 定义一个指针 i 用于比较当前前缀与当前字符串的字符
int i = 0;
// 逐字符比较前缀与当前字符串
while (i < prefix.size() && i < strs[strIndex].size()) {
// 如果当前字符不匹配,则跳出循环
if (prefix[i] != strs[strIndex][i]) break;
++i; // 如果匹配,继续比较下一个字符
}
// 更新前缀,取匹配的部分
prefix = prefix.substr(0, i);
}
// 返回最终的公共前缀
return prefix;
}
};队列
队列(queue)是一种遵循先入先出规则的线性数据结构。顾名思义,队列模拟了排队现象,即新来的人不断加入队列尾部,而位于队列头部的人逐个离开。
如图 4-1 所示,我们将队列头部称为“队首”,尾部称为“队尾”,将把元素加入队尾的操作称为“入队”,删除队首元素的操作称为“出队”。
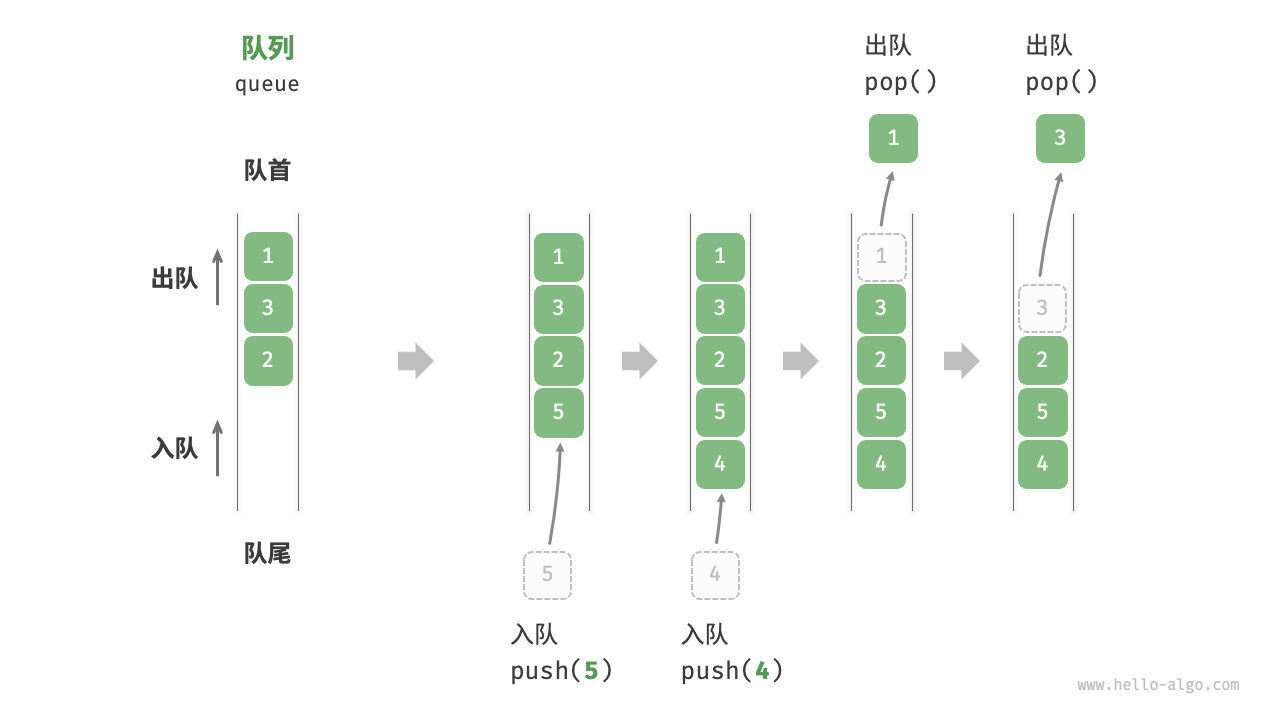
队列常用操作
1. 初始化
// 初始化一个存储 int 的队列
queue<int> q;
// 初始化一个存储 string 的队列
queue<string> q;2. 常用成员函数(方法)
// 返回队列是否为空
bool empty();
// 返回队列中元素的个数
size_t size();
// 将元素加入队尾
void push(const T& val);
// 返回队头元素的引用
T& front();
// 删除队头元素
void pop();队列结构比较简单,就一点需要注意,C++ 中队列的 pop() 方法一般都是 void 类型的,不会像其他语言那样同时返回被删除的元素,所以一般的做法是这样的。
int e = q.front(); // 先取出队头的元素
q.pop(); // 再取出队头的元素栈
栈(stack)是一种遵循先入后出逻辑的线性数据结构。
我们可以将栈类比为桌面上的一摞盘子,如果想取出底部的盘子,则需要先将上面的盘子依次移走。我们将盘子替换为各种类型的元素(如整数、字符、对象等),就得到了栈这种数据结构。
如图 5-1 所示,我们把堆叠元素的顶部称为“栈顶”,底部称为“栈底”。将把元素添加到栈顶的操作叫作“入栈”,删除栈顶元素的操作叫作“出栈”。
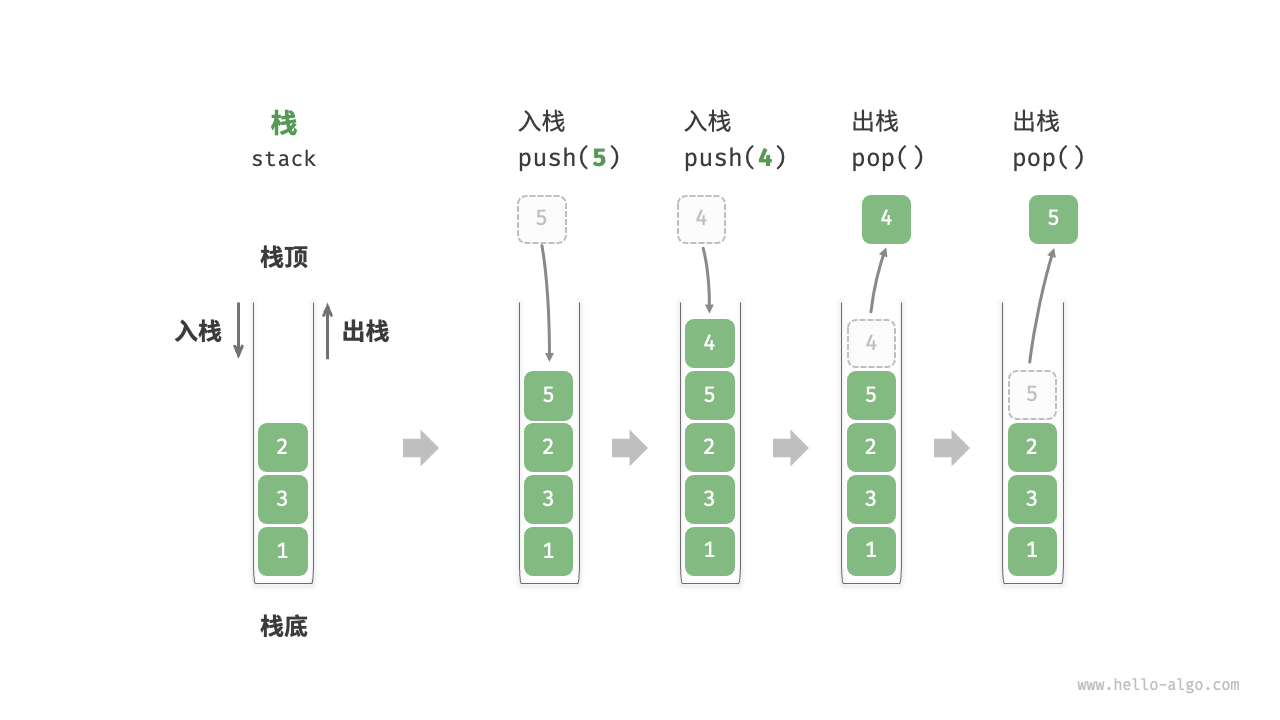
栈的常用操作
1. 初始化方法
// 初始化一个存储 int 的栈
stack<int> stk;
// 初始化一个储存 string 的栈
stack<string> stk;2. 常用成员函数(方法)
// 返回栈是否为空
bool empty();
// 返回栈中元素的个数
size_t size();
// 在栈顶添加元素
void push(const T& val);
// 返回栈顶元素的引用
T& top();
// 删除栈顶元素
void pop();栈例题 LC20 - 有效的括号
给定一个只包括 '(',')','{','}','[',']' 的字符串 s ,判断字符串是否有效。
有效字符串需满足:
- 左括号必须用相同类型的右括号闭合。
- 左括号必须以正确的顺序闭合。
- 每个右括号都有一个对应的相同类型的左括号。
示例 1:
输入:s = ”()”
输出:true
示例 2:
输入:s = ”()[]{}”
输出:true
示例 3:
输入:s = ”(]”
输出:false
示例 4:
输入:s = ”([])”
输出:true
思路
- 使用栈来处理括号匹配问题
- 遍历字符串中的每个字符
- 使用哈希表存储括号对应关系
- 分两种情况处理:
- 左括号: 入栈
- 右括号: 检查栈顶元素是否匹配
解法
class Solution {
public:
bool isValid(string s) {
// 创建一个栈用于存储左括号
stack<char> bracketStack {};
// 创建哈希表存储右括号和对应的左括号
unordered_map<char, char> mapping = {
{')', '('},
{']', '['},
{'}', '{'},
};
// 遍历字符串中的每个字符
for (char ch : s) {
// 如果是右括号
if (mapping.count(ch)) {
// 检查栈是否为空且栈顶元素是否匹配
if (!bracketStack.empty() && bracketStack.top() == mapping[ch]) {
bracketStack.pop(); // 匹配成功,弹出栈顶元素
continue;
}
return false; // 不匹配,返回false
}
// 如果是左括号,压入栈中
bracketStack.push(ch);
}
// 最后检查栈是否为空
return bracketStack.empty();
}
};要点说明
- 使用栈这种数据结构非常适合处理括号匹配问题
- 哈希表用于快速查找右括号对应的左括号
- 有三种情况会返回 false:
- 遇到右括号时栈为空
- 遇到右括号时栈顶元素不匹配
- 遍历结束后栈不为空
堆(优先队列)
堆(heap)是一种满足特定条件的完全二叉树,主要可分为两种类型,如图 6-1 所示。
- 小顶堆(min heap):任意节点的值 ≤ 其子节点的值。
- 大顶堆(max heap):任意节点的值 ≥ 其子节点的值。
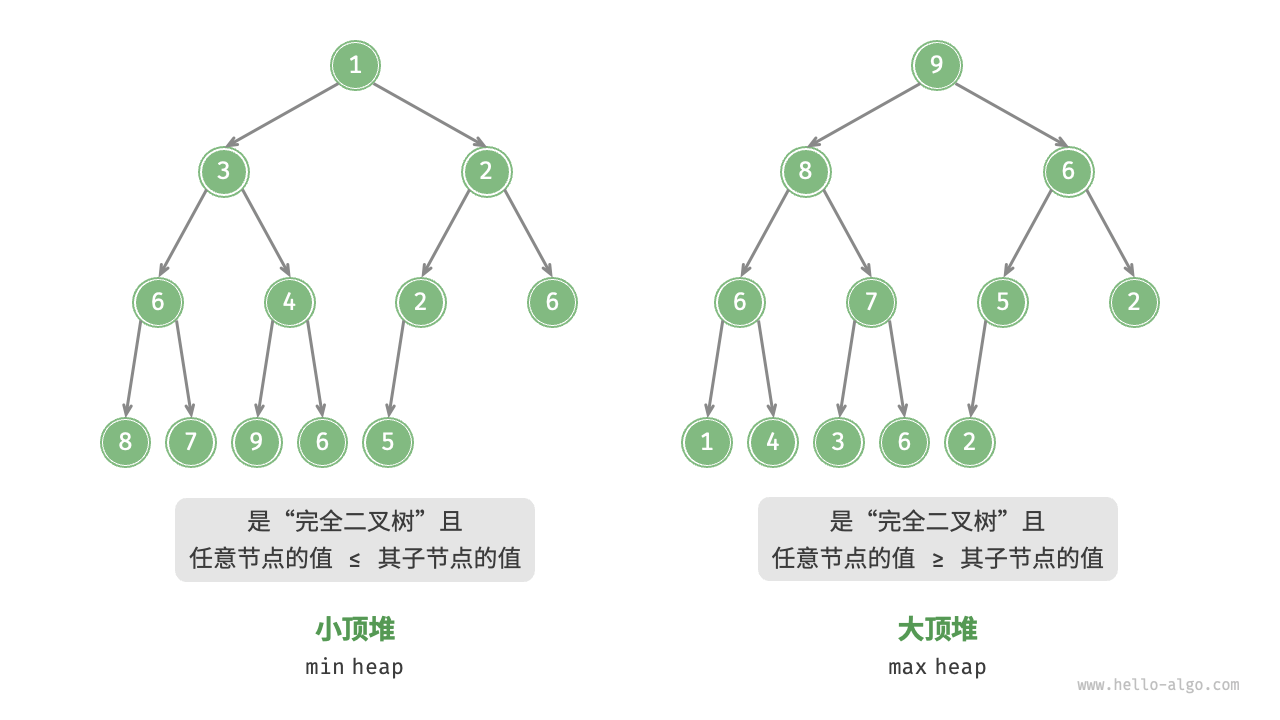
堆作为完全二叉树的一个特例,具有以下特性。
- 最底层节点靠左填充,其他层的节点都被填满。
- 我们将二叉树的根节点称为“堆顶”,将底层最靠右的节点称为“堆底”。
- 对于大顶堆(小顶堆),堆顶元素(根节点)的值是最大(最小)的。
堆的常用操作
需要指出的是,许多编程语言提供的是优先队列(priority queue),这是一种抽象的数据结构,定义为具有优先级排序的队列。
实际上,堆通常用于实现优先队列,大顶堆相当于元素按从大到小的顺序出队的优先队列。从使用角度来看,我们可以将“优先队列”和“堆”看作等价的数据结构。因此,本书对两者不做特别区分,统一称作“堆”。
堆的常用操作见表 6-1 ,方法名需要根据编程语言来确定。
| 方法名 | 描述 | 时间复杂度 |
|---|---|---|
push() | 元素入堆 | |
pop() | 堆顶元素出堆 | |
peek() | 访问堆顶元素(对于大 / 小顶堆分别为最大 / 小值) | |
size() | 获取堆的元素数量 | |
isEmpty() | 判断堆是否为空 |
在实际应用中,我们可以直接使用编程语言提供的堆类(或优先队列类)。
类似于排序算法中的“从小到大排列”和“从大到小排列”,我们可以通过设置一个 flag 或修改 Comparator 实现“小顶堆”与“大顶堆”之间的转换。代码如下所示:
/* 初始化堆 */
// 初始化小顶堆
priority_queue<int, vector<int>, greater<int>> minHeap;
// 初始化大顶堆
priority_queue<int, vector<int>, less<int>> maxHeap;
/* 元素入堆 */
maxHeap.push(1);
maxHeap.push(3);
maxHeap.push(2);
maxHeap.push(5);
maxHeap.push(4);
/* 获取堆顶元素 */
int peek = maxHeap.top(); // 5
/* 堆顶元素出堆 */
// 出堆元素会形成一个从大到小的序列
maxHeap.pop(); // 5
maxHeap.pop(); // 4
maxHeap.pop(); // 3
maxHeap.pop(); // 2
maxHeap.pop(); // 1
/* 获取堆大小 */
int size = maxHeap.size();
/* 判断堆是否为空 */
bool isEmpty = maxHeap.empty();
/* 输入列表并建堆 */
vector<int> input{1, 3, 2, 5, 4};
priority_queue<int, vector<int>, greater<int>> minHeap(input.begin(), input.end());哈希表与哈希集合
哈希表(hash table),又称散列表,它通过建立键 key 与值 value 之间的映射,实现高效的元素查询。具体而言,我们向哈希表中输入一个键 key ,则可以在 时间内获取对应的值 value 。
如图 7-1 所示,给定 n 个学生,每个学生都有“姓名”和“学号”两项数据。假如我们希望实现“输入一个学号,返回对应的姓名”的查询功能,则可以采用图 6-1 所示的哈希表来实现。

除哈希表外,数组和链表也可以实现查询功能,它们的效率对比如表 6-1 所示。
- 添加元素:仅需将元素添加至数组(链表)的尾部即可,使用 时间。
- 查询元素:由于数组(链表)是乱序的,因此需要遍历其中的所有元素,使用 时间。
- 删除元素:需要先查询到元素,再从数组(链表)中删除,使用 时间。
| 数组 | 链表 | 哈希表 | |
|---|---|---|---|
| 查找元素 | |||
| 添加元素 | |||
| 删除元素 |
观察发现,在哈希表中进行增删查改的时间复杂度都是 ,非常高效。
哈希集合可以看作只有 key 没有对应 value 版本的哈希表,常用于去重等操作。
哈希表常用操作
1. 初始化
// 初始化一个 key 为 int,value 为 int 的哈希表
unordered_map<int, int> mapping;
// 初始化一个 key 为 string,value 为 int 数组的哈希表
unordered_map<string, vector<int>> mapping;值得一提是,哈希表的值可以是任意类型的,但不是任意类型都可以作为哈希表的键。在我们刷算法题时,一般都使用 int 或 string 作为哈希表的键。
2. 常用成员函数(方法)
// 返回哈希表键值对个数
size_t size();
// 返回哈希表是否为空
bool empty();
// 返回哈希表中 key 出现的个数
// 因为哈希表不会出现重复的键,所以该方法只可能返回 0 或 1
// 可以用判断 key 是否出现在哈希表中
size_t count(const K& key);
// 通过 key 清除哈希表中的键值对
size_t erase(const K& key);3. 常见用法
vector<int> nums {1, 1, 3, 4, 5, 3, 6};
// 计数器
unordered_map<int, int> counter;
for (int num : nums) {
// 可以用方括号直接访问或修改对应的键
counter[num]++;
}
// 遍历哈希表中的键值对
for (auto& it : counter) {
int key = it.first;
int val = it.second;
cout << key << ": " << val << '\n';
}对于 std::unordered_map 有一点需要注意,用方括号 [] 访问其中的键 key 时,如果 key 不存在,则会自动创建 key,对应的值为值类型的默认值。
比如上面的例子中,counter[num]++ 这句代码实际上对应如下语句:
for (int num : nums) {
if (!counter.count(num)) {
// 新增一个键值对 num -> 0
counter[num] = 0;
}
counter[num]++;
}在计数器这个例子中,直接使用 counter[num]++ 是比较方便的写法,但是要注意 C++ 会自动创建不存在的键这个特性。有时候我们可能需要先显示地使用 count() 方法来判断键是否存在。
哈希集合常用操作
1. 初始化
// 初始化一个存储 int 的哈希集合
unordered_set<int> visited;
// 初始化一个存储 string 的哈希集合
unordered_set<string> visited;2. 常用成员函数(方法)
// 返回哈希集合的键值对个数
size_t size();
// 返回哈希集合是否为空
bool empty();
// 类似哈希表,如果 key 存在返回 1,否则返回 0
size_t count(const K& key);
// 向集合中插入一个元素 key
pair<iterator, bool> insert(const K& key);
// 删除哈希集合中的元素 key
// 成功返回 1,不存在返回 0
size_t erase(const K& key);哈希表例题 LC1 - 两数之和
给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。
你可以假设每种输入只会对应一个答案,并且你不能使用两次相同的元素。
你可以按任意顺序返回答案。
示例 1:
输入:nums = [2,7,11,15], target = 9
输出:[0,1]
解释:因为 nums[0] + nums[1] == 9 ,返回 [0, 1] 。
示例 2:
输入:nums = [3,2,4], target = 6
输出:[1,2]
示例 3:
输入:nums = [3,3], target = 6
输出:[0,1]
思路
- 使用哈希表存储遍历过的数字及其下标
- 遍历数组,使用哈希表查找是否存在 target - nums[i] (互补数)
- 若找到互补数,返回当前下标和互补数下标
- 若未找到,将当前数字及下标加入哈希表
解法
class Solution {
public:
vector<int> twoSum(vector<int>& nums, int target) {
// 哈希表存储 <数字, 下标>
unordered_map<int, int> memo;
// 遍历数组
for (int i = 0; i < nums.size(); ++i) {
// 查找互补数
if (memo.count(target - nums[i])) {
return {i, memo[target - nums[i]]};
}
// 存储当前数字和下标
memo.insert({nums[i], i});
}
return {};
}
};哈希集合例题 LC217 - 存在重复元素
给你一个整数数组 nums 。如果任一值在数组中出现 至少两次 ,返回 true ;如果数组中每个元素互不相同,返回 false 。
示例 1:
输入:nums = [1,2,3,1]
输出:true
解释:
元素 1 在下标 0 和 3 出现。
示例 2:
输入:nums = [1,2,3,4]
输出:false
解释:
所有元素都不同。
示例 3:
输入:nums = [1,1,1,3,3,4,3,2,4,2]
输出:true
思路
- 根据
nums数组构造哈希集合,该数据类型能保证不会重复插入相同元素 - 比对
nums数组长度和哈希集合长度,相同则没有重复元素,不同则有重复元素
解法
class Solution {
public:
bool containsDuplicate(vector<int>& nums) {
unordered_set<int> memo(nums.begin(), nums.end());
return memo.size() != nums.size();
}
};unordered_map (unordered_set) vs. std::map (std::set)
基本特性
| 特性 | map (set) | unordered_map (unordered_set) |
|---|---|---|
| 内部实现 | 红黑树 | 哈希表 |
| 元素排序 | 自动排序 | 无序 |
| 内存占用 | 较低 | 较高 |
| 迭代器 | 双向迭代器 | 前向迭代器 |
时间复杂度对比
| 操作 | map (set) | unordered_map (unordered_set) |
|---|---|---|
| 插入 | 平均、 最坏 | |
| 删除 | 平均、 最坏 | |
| 查找 | 平均、 最坏 |